Deployment Layouts
The kubernetes logging helm chart supports a number of deployment layouts of OpenSearch and other components depending on the concrete purpose and size of the cluster.
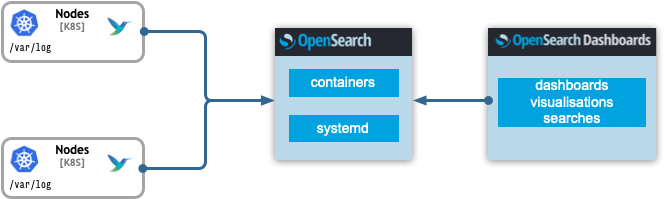
Single node OpenSearch
opensearch:
single_node: true
fluentbit:
containersLogsHostPath: /var/log/pods
journalsLogsHostPath: /var/log
containersRuntime: docker
kafka:
false:
This layout is the simplest possible requiring the least compute and memory resources. It comprises of the log shippers, a single OpenSearch node and a single OpenSearchDashabord UI. The log shippers are FluentBits deployed on each kubernetes node mounting the host filesystem. Because the locations of the containers logs or the host journals can vary, those locations have to be adapted accordingly in the FluentBit configuration. The logs are directly send to the Opensearch node for indexing without the need of a message broker in between.
Recommendation: Although the single node can be scaled by simply increasing the replicas in the “data” configuration, this setup is most suitable for development environments like minikube or kind clusters.
Multi node OpenSearch
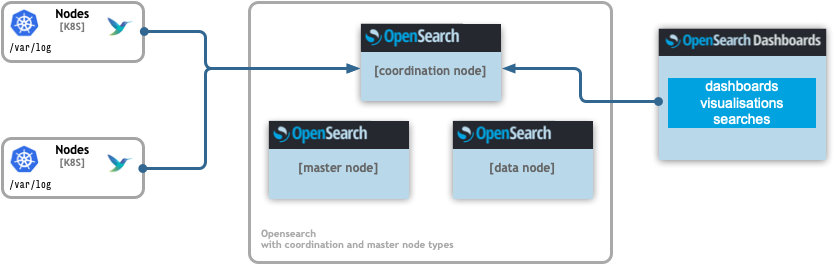
OpenSearch supports dedicated node types based on specific functions in the cluster. A coordination node, data node and cluster manager node forming an OpenSearch cluster can be deployed when single_node option is disabled.
opensearch:
single_node: false
Scaled multi node OpenSearch in production
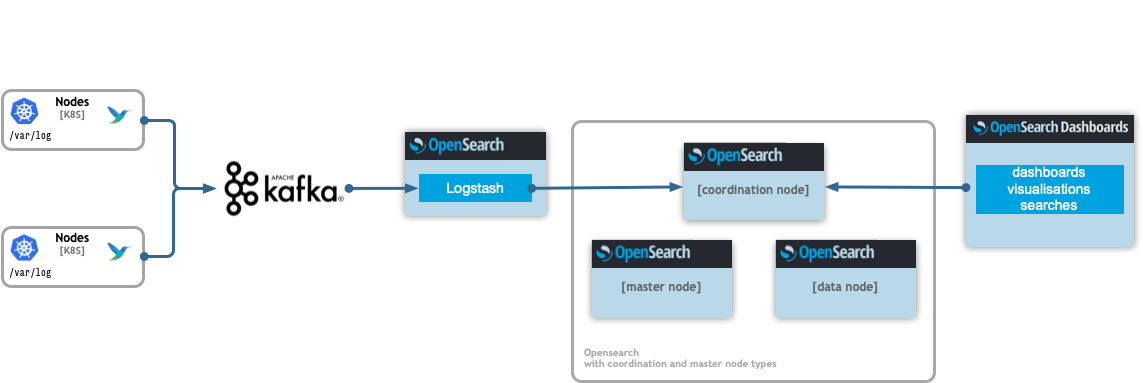
When the setup is deployed in a production environment both aspects for reliably and throughout of the logs streams are addressed by the helm chart with the introduction of a message broker. A running message broker (Kafka) effectively accumulates spikes of logs volumes or downtimes of the backend OpenSearch cluster.
Note:
Kafka and Logstash needs to be enabled as well!.Delivery chain is:
Kafka->Logstash->OpenSearch
Even more importantly each component can be scaled horizontally insuring better reliability.
opensearch:
single_node: false
data:
replicas: 3
clusterManager:
replicas: 3
client:
replicas: 3
kafka:
enabled: true
replicas: 3
logstash:
enabled: true
replicas: 3
#and so on
Additionally each type of workload scheduling strategy can be further optimized by defining node and pods (anti)affinity rules.
For example for stateful sets like Kafka’s or data nodes following affinity strategy guarantees that pods will be scheduled on different kubernetes nodes.
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: type
operator: In
values:
# with the corresponding label
- kafka
topologyKey: kubernetes.io/hostname
Or in the case of a deployments like the OpenSearch coordination nodes or Logstashes a spread of pods over nodes can be achieved with:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
# with the corresponding label
type: client